Semantic
Web, còn được gọi là Web 3.0, là một phần mở rộng của thế giới web được định
nghĩa bởi Hiệp hội World Wide Web (W3C). Chuẩn Semantic nhấn mạnh đến việc sử dụng
các định dạng dữ liệu và các giao thức chung để mọi trang web, mọi dịch vụ
online đều có thể giao tiếp với nhau một cách dễ dàng. Hiệp hội thậm chí còn đề
ra một bộ khung cho định dạng dữ liệu đó để mọi người có thể làm theo. Trong
bài này, mời các bạn hiểu rõ hơn về Web 3.0 cũng như ảnh hưởng có nó đến tương
lai của thế giới công nghệ nhé.
Web 1.0 và
2.0
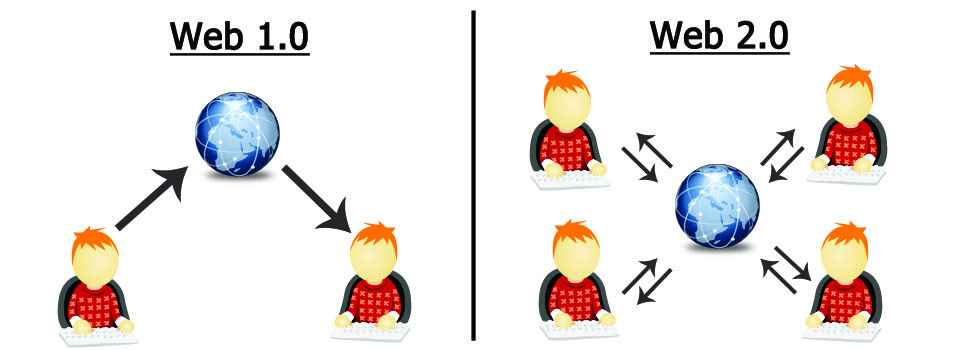
Đến
nay không có định nghĩa cụ thể về Web 1.0, nhưng người ta thường xem những ngày
đầu của World Wide Web là Web 1.0. Vào thời đó, khoảng từ năm 1998 trở về trước,
các trang web chỉ cung cấp thông tin một chiều. Chủ sở hữu website hoặc các
doanh nghiệp là những người đưa thông tin, còn người dùng như chúng ta chỉ có
thể đọc thông tin trên đó mà không tương tác được gì thêm. Sự thụ động của
thông tin khiến tiềm năng của World Wide Web nói riêng và Internet nói chung
không được khai thác hết, nó chưa thật sự đi sâu vào từng ngõ ngách của đời sống
con người.
Dần
dần, các trang web 1.0 bắt đầu đưa những phần bình luận nhỏ, những mục tương
tác với người đọc vào website của mình. Tuy nhiên, do năng lực xử lý và lưu trữ
hạn chế của máy tính thời kì đó nên những mục như thế này không thật sự phổ biến
hoặc chỉ hiển thị một cách giới hạn.
Cụm
từ Web 2.0 được sử dụng lần đầu vào năm 1999 khi Darcy DiNucci, một chuyên viên
tư vấn về thiết kế hệ thống thông tin. Bà viết như sau: "Web mà chúng ta
đang biết, vốn chỉ đơn giản là tải về hình ảnh vào một cửa sổ trình duyệt tĩnh,
chỉ là một phần của tương lai Web. Những dấu hiệu đầu tiên của Web 2.0 đã bắt đầu
xuất hiện, và chúng ta chỉ mới thấy được những bước đi đầu tiên. Web sắp tới có
thể hiểu như là nơi mà các hành động xảy ra...." DiNucci còn nói rằng Web
2.0 sẽ xuất hiện không chỉ trên máy tính mà còn ở TV, xe hơi, điện thoại, máy
chơi game, thậm chí cả lò vi sóng.
Đến
khoảng năm 2002, cụm từ Web 2.0 lại xuất hiện trở lại. Lần này, Web 2.0 được người
ta xem như một thế hệ website mới nhấn mạnh vào sự tương tác với người dùng, người
dùng sẽ là những người đóng góp nội dung, ngoài ra còn phải chú trọng đến tính
dễ dùng nữa. Những ví dụ của Web 2.0 có thể thấy khắp mọi nơi: Diễn đàn (như
Tinh tế chẳng hạn), Mạng xã hội (Facebook, Twitter, YouTube), Blog, các trang Wiki,
các ứng dụng nền web, ứng dụng lấy dữ liệu từ web và rất nhiều những thứ khác nữa.
Chưa kể, người ta còn có thể cùng nhau làm việc, cùng nhau gặp gỡ và hợp tác nhờ
vào Web 2.0.

Nói
về mặt kĩ thuật, một trong những sự khác biệt lớn giữa Web 1.0 và 2.0 đó là việc
các website hay các ứng dụng web tách những yêu cầu gửi lên server ra riêng so
với dữ liệu phản hồi nhận về. Kĩ thuật này gọi là yêu cầu không đồng bộ
(asynchronously), nó cho phép bạn vừa làm việc khác trong lúc chờ một phần của
website được tải về. Còn ở Web 1.0, bạn muốn là gì thì cũng phải đợi web load
xong hết. Ví dụ, nếu bạn comment vào Tinh tế thì phải load lại cả trang mới thấy
comment mới, còn như Tinh tế hiện giờ thì điều này là không cần thiết. Gửi yêu
cầu theo kiểu asynchronous còn giúp giảm tải cho server.
Web 3.0 -
Semantic Web
Theo
W3C, định nghĩa về Semantic Web như sau: "Semantic Web cung cấp một bộ
khung chung để giúp dữ liệu có thể được chia sẻ và tái sử dụng xuyên suốt nhiều
ứng dụng, doanh nghiệp và các biên giới cộng đồng". Từ này cũng đã được
Tim Berners-Lee, cha đẻ của World Wide Web, dùng để chỉ một mạng lưới dữ liệu
có thể được xử lý bởi nhiều cỗ máy khác nhau. Hiện có nhiều ý kiến tỏ ra nghi
ngại về Semantic Web, tuy nhiên nhiều thực tế về việc áp dụng cho các lĩnh vực
công nghiệp, sinh học và khoa học nhân văn đã cho thấy rằng ý tưởng của
Semantic Web là rất khả thi.
Như
vậy, chúng ta có thể thấy Web 3.0 chính là Web 2.0 nhưng được tiến hóa lên một
bậc cao hơn, trong đó nhấn mạnh đến việc chia sẻ dữ liệu giữa các website với
nhau hoặc các dịch vụ nói chung. Ngay cả việc trao đổi dữ liệu giữa một website
với ứng dụng di động của chính website đó cũng có thể được xem như là một phần
của Web 3.0.
Vậy
làm sao để có thể xài các "chuẩn chung" mà chúng ta đã thấy nhiều lần
trong bài viết này? Hiệp hội W3C đưa ra một số đề xuất về các định dạng chung
chuyên dùng cho việc lưu trữ, gửi nhận hoặc chia sẻ dữ liệu, trong đó có 2 thứ
hiện đã xuất hiện nhiều là XML và JSON. Một vài thứ khác nữa là OWL và RDF nhưng
chúng ta sẽ không đề cập trong bài này. Bạn nào thích thì có thể xem thêm về
RDF ở đây.
XML
(EXtensible Markup Language) là một định dạng dữ liệu sử dụng các tag gần giống
như HTML, tuy nhiên nó chỉ dùng cho dữ liệu chứ không phải để hiển thị website.
Ví dụ, các website hoặc app có thể dùng XML để lưu thông tin về khách hàng,
doanh số sản phẩm, hồ sơ người dùng, sơ đồ trang, cấu hình app và nhiều thứ
khác. File Word, Excel, PowerPoint dạng DOCX hay XLSX mà bạn đang dùng cũng được
xây dựng dựa trên định dạng XML đấy. Bên dưới là một đoạn XML mẫu.

JSON
(JavaScript Object Notation) cũng là một định dạng dữ liệu tương tự như XML, chức
năng và tác dụng cũng y hệt. Tuy nhiên, nó được xây dựng theo hình mẫu của một
mảng dữ liệu đa chiều, và JSON được xem là dễ đọc bằng mắt thường hơn so với
XML. Hiện nay nhiều trang web, dịch vụ cũng đang xài JSON để trao đổi dữ liệu
giữa trình duyệt / app với máy chủ. Thao tác đăng nhập vào một website hay một
app bằng tài khoản Facebook cũng xài dữ liệu dạng JSON để nói với web biết rằng
bạn có cho phép đăng nhập hay không, và có bị giới hạn gì hay không. Dữ liệu thời
tiết lấy từ Yahoo Weather cũng ở dạng JSON, dữ liệu khi cần truy vấn thông tin
video từ YouTube cũng JSON nốt. Bên dưới là một đoạn JSON mẫu, trong đó chứa
cùng dữ liệu như ví dụ với XML ở trên.

Với
Web 2.0, các trang web sẽ dùng HTML để hiển thị ra cho bạn xem, để kết nối giữa
các trang, các thành phần với nhau. Còn XML, JSON, OWL và RDF sẽ làm nhiệm vụ
truyền tải dữ liệu và định nghĩa các thứ cụ thể, ví dụ như người, sự vật, sự việc,
địa điểm, thời gian...
Như
các bạn có thể thấy, ở thời Web 1.0 và buổi đầu của Web 2.0, dữ liệu không được
lưu theo những định dạng chung như XML hay JSON, do đó một website sẽ gặp khó
khăn khi cần giao tiếp với một website khác. Dữ liệu đưa ra sẽ là gì? Làm thế
nào để đọc nó? Phần nào trong dữ liệu là quan trọng và phần nào không? Những
câu hỏi này khiến việc bắt tay sẽ các web trở nên khó khăn. Bản thân nhà phát
triển web cũng mất công hơn, tốn nhiều thời gian hơn khi phải viết ra những đoạn
mã để đọc dữ liệu không theo chuẩn chung.
Lợi ích của
Web 3.0
Như
đã nói ở trên, Web 3.0 nhấn mạnh vào tính chia sẻ của dữ liệu. Điều đó sẽ giúp
các website khi cần nói chuyện với nhau sẽ dễ dàng hơn, nhanh chóng hơn, chính
xác hơn. Lập trình viên của các bên cần giao tiếp cũng đỡ cực hơn trong việc viết
ra những công cụ dùng để đọc dữ liệu, họ chỉ cần thông báo cho bên kia biết rằng
họ gửi dữ liệu gì qua và bên kia viết phần mềm để đọc đúng những thứ đó là được.
Hiện
tại tác dụng của các chuẩn Web 3.0 cũng đã bắt đầu bộc lộ: bạn không cần phải
đăng kí khi xài một web hay app nào đó, có thể đăng nhập bằng Facebook ngay.
Các app tin tức có thể truy vấn dữ liệu thời tiết từ Yahoo dễ dàng, không cần
phải tự mình đi tìm hay thu thập dữ liệu phức tạp. Dropbox có thể được tích hợp
nhanh với Microsoft Office cũng có thể xem như một ví dụ khác.

Nghĩ
rộng ra, chúng ta có thể tưởng tượng đến thế giới của Internet of Things, nơi
mà mọi thiết bị đều được kết nối vào Internet. Hàng trăm triệu cảm biến từ các
hãng sản xuất khác nhau sẽ ghi nhận và gửi dữ liệu về các trung tâm phân tích,
và nếu không có một chuẩn dữ liệu chung thì dữ liệu của hãng này sẽ rất khó xài
chung với hãng khác. Giả sử như bạn đang cần theo dõi tình trạng y tế của mình
thì dữ liệu từ bộ đo huyến áp do công ty A làm sẽ khác hẳn với dữ liệu từ bộ đo
điện tim do công ty B sản xuất, vậy thì bạn không thể kết hợp chúng lại để đưa
ra những báo cáo hay lời khuyên được. Hay như trong nhà bạn, dữ liệu từ cảm biến
báo khói X sẽ không thể kết hợp với dữ liệu do cảm biến trộm do đơn vị Y làm
ra. Cũng từ đây là mà tính cá nhân hóa với dữ liệu sẽ cao hơn bao giờ hết.
Sự
trao đổi thông tin của Web 3.0 còn giúp quá trình tìm kiếm thông tin trên
Internet được dễ dàng hơn, hiệu quả hơn và trả về đúng thứ bạn cần hơn. Đó là
do các website sử dụng dữ liệu theo định dạng chuẩn, và những bộ máy như Google
Search, Bing Search, Yahoo Search chỉ việc đọc dữ liệu đó để phân tích và ghi
nhớ mà thôi, không cần phải đi xuyên qua những file HTML phức tạp và không theo
cấu trúc nhất định.
Cũng
nhờ sự trao đổi nói trên mà các dịch vụ web sẽ hiểu người dùng hơn, hiểu rõ nhu
cầu của họ cần gì, họ đang gõ gì, đang muốn tìm kiếm thứ gì bằng cách học hỏi,
lấy dữ liệu từ nhiều trang web khác. Có người nói thời đại Web 1.0 chỉ là đọc,
Web 2.0 là đọc và viết, và Web 3.0 là đọc, viết và hiểu.
Và
cuối cùng, Web 3.0 sẽ giúp dữ liệu được hiển thị theo thời gian thực một cách
nhanh chóng và hiệu quả hơn. Chúng ta sẽ có nhiều những ứng dụng dành cho kinh
doanh, giáo dục, bán lẻ, kho bãi... với thông tin được cập nhật từng phút từng
giây mà không phải load lại cả trang web. Nói chung là các luồng dữ liệu sẽ đi
vào đi ra liên tục mang cho bạn những thông tin mới nhất, đáng giá nhất.
Những
thách thức hiện tại
Tất
nhiên, cái gì cũng có hai mặt, và Web 3.0 cũng thế. Một số những thách thức mà
Web 3.0 phải đối mặt bao gồm:
1.
Khối lượng dữ liệu khổng lồ: World
Wide Web hiện có cả tỉ trang web trên đó, mỗi trang web lại tạo ra một lượng dữ
liệu to nhỏ khác nhau. Các cảm biến, thiết bị di động, hành vi của người dùng lại
tạo thêm một đống nữa. Chính vì thế, nếu các nhà thiết kế, nhà phát triển web
không kịp thay đổi công nghệ thì sẽ không thể đảm đương được hết những dữ liệu
này, và không mang lại hiệu quả tối đa cho người dùng. Những hệ thống tự động
hóa cũng phải được thiết kế lại để xử lý lượng dữ liệu đầu vào rất rất lớn. Dữ
liệu trùng lặp cũng là một vấn đề cần được cân nhắc.

2. Dữ liệu không rõ ràng: những từ như
"trẻ", "cao" hoặc "lớn" có thể được xem là dữ liệu
không rõ ràng, hay nói cách khác là quá chung chung. Như thế nào là trẻ? Như thế
nào là cao, cao bao nhiêu? Lớn là gì, lớn ra sao, so với cái gì? Kết quả là những
truy vấn tìm kiếm của người dùng cũng sẽ chung chung như thế, ngoài ra còn có sự
chung chung trong dữ liệu được cung cấp bởi các công ty / tổ chức, hoặc sự
chung chung trong các cơ sở dữ liệu kiến thức sẽ khiến việc xử lý, giao tiếp trở
nên khó khăn.
3.
Sự thiếu nhất quán: Mặc dù đã có các
chuẩn chung nhưng chắc chắn sẽ luôn có sự khác biệt xuất hiện Có thể là vì giải
pháp 1 tốt hơn giải pháp 2 nhưng giải pháp 2 lại dễ dùng hơn nên cả hai tồn tại
song song. Điều đó tạo ra sự thiếu nhất quán trong thế giới Word Wide Web. Như
hiện nay cũng thế, Flash và Silverlight, JSON và XML,...
4.
Bảo mật: khi dữ liệu được chia sẻ dễ
dàng thì cũng mang theo nguy cơ cao về an toàn thông tin. Ví dụ, thông tin đó
có thể bị giả mạo, có thể bị thay thế giữa lúc đang truyền đi, thông tin mang
theo mã độc, thông tin không được mã hóa...
Vẫn
còn nhiều nhiều những vấn đề khác, và tất cả đều cần đến một hoặc một số giải
pháp đã có sẵn hoặc chưa có. Nhưng tóm lại, Web 3.0 là xu hướng không thể chối
bỏ, và nó sẽ dần rõ nét hơn trong thời gian tới.
Nguồn:
Wikipedia, How Stuff Works, LifeBoat